I want to start off this question by saying that I'm looking for more of a conceptual understanding of this term in a simple regression model, not a mathematical one.
In econometrics, simple linear regression has an "error term", called mu, which represents "factors other than x that effect y, or unobserved data." In a statistics class, this term is called "statistical error" or "noise" treated as epsilon, which again is random noise in the real world our model cannot capture.
In Introduction to Statistical Learning, this term is referred to as "irreducible error," and is a quantity that represents unmeasured variables that we haven't measured, or simply just unmeasurable variation in real world data. The authors bifurcate between this term and reducible error.
Here is where my confusion lies: in a theoretically, completely deterministic world, where we have an infinite amount of data, is this "irreducible error" theoretically reducible? That is to say, if in this theoretical world, our covariate, college GPA, could be mapped to our response, say "Salary," could this term technically be zero?
I understand that in the world we live in, there is always unmeasurable variation in data, and that we'll never have access to an infinite amount of data or know beforehand every single covariate, thus this error arises. But say we had 5 data points, and this was our "theoretical population," would this "irreducible error" term disappear?
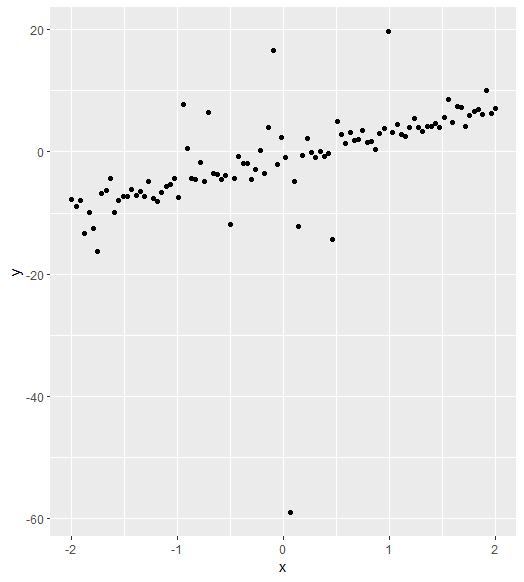
For example, in Introduction to Statistical learning, they have this image:

My confusion in this image arises from the fact that this data was simulated, and so we actually know the true underlying function f. But if that is the case, why is there still error? If we know f, why can't we perfectly fit this function to the data? And if this data was simulated based on f, why doesn't the simulation produce data points on the function f?
I know it may seem like a silly question, but I'm trying to understand the nuance here. Many thanks to your help in advance.