Every website and web app should have a service worker | Go Make Things
Needless to say, I agree with this sentiment.
I’ve worked with a lot of browser technology over the years. Service workers are pretty mind-blowing.
Needless to say, I agree with this sentiment.
I’ve worked with a lot of browser technology over the years. Service workers are pretty mind-blowing.
I’m quite sure this is of no interest to anyone but me, but I finally managed to fix a longstanding weird issue with my website.
I realise that me telling you about a bug specific to my website is like me telling you about a dream I had last night—fascinating for me; incredibly dull for you.
For some reason, my site was being brought to its knees anytime I syndicated a note to Mastodon. I rolled up my sleeves to try to figure out what the problem could be. I was fairly certain the problem was with my code—I’m not much of a back-end programmer.
My tech stack is classic LAMP: Linux, Apache, MySQL and PHP. When I post a note, it gets saved to my database. Then I make a curl request to the Mastodon API to syndicate the post over there. That’s when my CPU starts climbing and my server gets all “bad gateway!” on me.
After spending far too long pulling apart my PHP and curl code, I had to come to the conclusion that I was doing nothing wrong there.
I started watching which processes were making the server fall over. It was MySQL. That seemed odd, because I’m not doing anything too crazy with my database reads.
Then I realised that the problem wasn’t any particular query. The problem was volume. But it only happened when I posted a note to Mastodon.
That’s when I had a lightbulb moment about how the fediverse works.
When I post a note to Mastodon, it includes a link back to the original note to my site. At this point Mastodon does its federation magic and starts spreading the post to all the instances subscribed to my account. And every single one of them follows the link back to the note on my site …all at the same time.
This isn’t a problem when I syndicate my blog posts, because I’ve got a caching mechanism in place for those. I didn’t think I’d need any caching for little ol’ notes. I was wrong.
A simple solution would be not to include the link back to the original note. But I like the reminder that what you see on Mastodon is just a copy. So now I’ve got the same caching mechanism for my notes as I do for my journal (and I did my links while I was at it). Everything is hunky-dory. I can syndicate to Mastodon with impunity.
See? I told you it would only be of interest to me. Although I guess there’s a lesson here. Something something caching.
The caching strategy for The Session that I wrote about is working a treat.
There are currently about 45,000 different tune settings on the site. One week after introducing the server-side caching, over 40,000 of those settings are already cached.
But even though it’s currently working well, I’m going to change the caching mechanism.
The eagle-eyed amongst you might have raised an eagle eyebrow when I described how the caching happens:
The first time anyone hits a tune page, the ABCs getting converted to SVGs as usual. But now there’s one additional step. I grab the generated markup and send it as an Ajax payload to an endpoint on my server. That endpoint stores the sheetmusic as a file in a cache.
I knew when I came up with this plan that there was a flaw. The endpoint that receives the markup via Ajax is accepting data from the client. That data could be faked by a malicious actor.
Sure, I’m doing a whole bunch of checks and sanitisation on the server, but there’s always going to be a way of working around that. You can never trust data sent from the client. I was kind of relying on security through obscurity …except it wasn’t even that obscure because I blogged about it.
So I’m switching over to using a headless browser to extract the sheetmusic. You may recall that I wrote:
I could spin up a headless browser, run the JavaScript and take a snapshot. But that’s a bit beyond my backend programming skills.
That’s still true. So I’m outsourcing the work to Browserless.
There’s a reason I didn’t go with that solution to begin with. Like I said, over 40,000 tune settings have already been cached. If I had used the Browserless API to do that work, it would’ve been quite pricey. But now that the flood is over and there’s a just a trickle of caching happening, Browserless is a reasonable option.
Anyway, that security hole has now been closed. Thank you to everyone who wrote in to let me know about it. Like I said, I was aware of it, but it was good to have it confirmed.
Funnily enough, the security lesson here is the same as my conclusion when talking about performance:
If that means shifting the work from the browser to the server, do it!
Performance is a high priority for me with The Session. It needs to work for people all over the world using all kinds of devices.
My main strategy for ensuring good performance is to diligently apply progressive enhancement. The core content is available to any device that can render HTML.
To keep things performant, I’ve avoided as many assets (or, more accurately, liabilities) as possible. No uneccessary images. No superfluous JavaScript libraries. Not even any web fonts (gasp!). And definitely no third-party resources.
The pay-off is a speedy site. If you want to see lab data, run a page from The Session through lighthouse. To see field data, take a look at data from Chrome UX Report (Crux).
But the devil is in the details. Even though most pages on The Session are speedy, the outliers have bothered me for a while.
Take a typical tune page on the site. The data is delivered from the server as HTML, which loads nice and quick. That data includes the notes for the tune settings, written in ABC notation, a nice lightweight text format.
Then the enhancement happens. Using Paul Rosen’s brilliant abcjs JavaScript library, those ABCs are converted into SVG sheetmusic.
So on tune pages there’s an additional download for that JavaScript library. That’s not so bad though—I’m using a service worker to cache that file so there’ll only ever be one initial network request.
If a tune has just a few different versions, the page remains nice and zippy. But if a tune has lots of settings, the computation starts to add up. Converting all those settings from ABC to SVG starts to take a cumulative toll on the main thread.
I pondered ways to avoid that conversion step. Was there some way of pre-generating the SVGs on the server rather than doing it all on the client?
In theory, yes. I could spin up a headless browser, run the JavaScript and take a snapshot. But that’s a bit beyond my backend programming skills, so I’ve taken a slightly different approach.
The first time anyone hits a tune page, the ABCs getting converted to SVGs as usual. But now there’s one additional step. I grab the generated markup and send it as an Ajax payload to an endpoint on my server. That endpoint stores the sheetmusic as a file in a cache.
Next time someone hits that page, there’s a server-side check to see if the sheetmusic has been cached. If it has, send that down the wire embedded directly in the HTML.
The idea is that over time, most of the sheetmusic on the site will transition from being generated in the browser to being stored on the server.
So far it’s working out well.
Take a really popular tune like The Lark In The Morning. There are twenty settings, and each one has four parts. Previously that would have resulted in a few seconds of parsing and rendering time on the main thread. Now everything is delivered up-front.
I’m not out of the woods. A page like that with lots of sheetmusic and plenty of comments is going to have a hefty page weight and a large DOM size. I’ve still got a fair bit of main-thread work happening, but now the bulk of it is style and layout, whereas previously I had the JavaScript overhead on top of that.
I’ll keep working on it. But overall, the speed improvement is great. A typical tune page is now very speedy indeed.
It’s like a microcosm of web performance in general: respect your users’ time, network connection and battery life. If that means shifting the work from the browser to the server, do it!
Damn, I wish I had thought of giving this answer to the prompt, “What is one thing people can do to make their website better?”
If you do nothing else, this will be a huge boost to your site in 2022.
Chris’s piece is a self-contained tutorial!
This is terrific! Jeremy shows how you can implement a fairly straightforward service worker for performance gains, but then really kicks it up a notch with a recipe for turning a regular website into a speedy single page app without framework bloat.
When I was speaking at conferences last year about service workers, I’d introduce the Cache API. I wanted some way of explaining the difference between caching and other kinds of storage.
The way I explained was that, while you might store stuff for a long time, you’d only cache stuff that you knew you were going to need again. So according to that definition, when you make a backup of your hard drive, that’s not caching …becuase you hope you’ll never need to use the backup.
But that explanation never sat well with me. Then more recently, I was chatting with Amber about caching. Once again, we trying to define the difference between, say, the Cache API and things like LocalStorage and IndexedDB. At some point, we realised the fundamental difference: caches are for copies.
Think about it. If you store something in LocalStorage or IndexedDB, that’s the canonical home for that data. But anything you put into a cache must be a copy of something that exists elsewhere. That’s true of the Cache API, the browser cache, and caches on the server. An item in one of those caches is never the original—it’s always a copy of something that has a canonical home elsewhere.
By that definition, backing up your hard drive definitely is caching.
Anyway, I was glad to finally have a working definition to differentiate between caching and storing.
Chris Ferdinandi blogs every day about the power of vanilla JavaScript. For over a week now, his daily posts have been about service workers. The cumulative result is this excellent collection of resources.
Aaron outlines some sensible strategies for serving up images, including using the Cache API from your service worker script.
Yesterday I wrote about how much I’d like to see silent push for the web:
I’d really like silent push for the web—the ability to update a cache with fresh content as soon as it’s published; that would be nifty! At the same time, I understand the concerns. It feels more powerful than other permission-based APIs like notifications.
Today, John Holt Ripley responded on Twitter:
hi there, just read your blog post about Silent Push for acthe web, and wondering if Periodic Background Sync would cover a few of those use cases?
Periodic background sync looks very interesting indeed!
It’s not the same as silent push. As the name suggests, this is about your service worker waking up periodically and potentially fetching (and caching) fresh content from the network. So the service worker is polling rather than receiving a push. But I’ll take it! It’s definitely close enough for the kind of use-cases I’ve been thinking about.
Interestingly, periodic background sync also ties into the other part of what I was writing about: permissions. I mentioned that adding a site the home screen could be interpreted as a signal to potentially allow more permissions (or at least allow prompts for more permissions).
Well, Chromium has a document outlining metrics for attempting to gauge site engagement. There’s some good thinking in there.
After Indie Web Camp in Berlin last year, I wrote about Seb’s nifty demo of push without notifications:
While I’m very unwilling to grant permission to be interrupted by intrusive notifications, I’d be more than willing to grant permission to allow a website to silently cache timely content in the background. It would be a more calm technology.
Phil Nash left a comment on the Medium copy of my post explaining that Seb’s demo of using the Push API without showing a notification wouldn’t work for long:
The browsers allow a certain number of mistakes(?) before they start to show a generic notification to say that your site sent a push notification without showing a notification. I believe that after ~10 or so notifications, and that’s different between browsers, they run out of patience.
He also provided me with the name to describe what I’m after:
You’re looking for “silent push” as are many others.
Silent push is something that is possible in native apps. It isn’t (yet?) available on the web, presumably because of security concerns.
It’s an API that would ripe for abuse. I mean, just look at the mess we’ve made with APIs like notifications and geolocation. Sure, they require explicit user opt-in, but these opt-ins are seen so often that users are sick of seeing them. Silent push would be one more permission-based API to add to the stack of annoyances.
Still, I’d really like silent push for the web—the ability to update a cache with fresh content as soon as it’s published; that would be nifty! At the same time, I understand the concerns. It feels more powerful than other permission-based APIs like notifications.
Maybe there could be another layer of permissions. What if adding a site to your home screen was the first step? If a site is running on HTTPS, has a service worker, has a web app manifest, and has been added to the homescreen, maybe then and only then should it be allowed to prompt for permission to do silent push.
In other words, what if certain very powerful APIs were only available to progressive web apps that have successfully been added to the home screen?
Frankly, I’d be happy if the same permissions model applied to web notifications too, but I guess that ship has sailed.
Anyway, all this is pure conjecture on my part. As far as I know, silent push isn’t on the roadmap for any of the browser vendors right now. That’s fair enough. Although it does annoy me that native apps have this capability that web sites don’t.
It used to be that there was a long list of features that only native apps could do, but that list has grown shorter and shorter. The web’s hare is catching up to native’s tortoise.
Here’s a nice example of showing pages offline. It’s subtly different from what I’m doing on my own site, which goes to show that there’s no one-size-fits-all recipe when it comes to offline strategies.
This is a great little technique from Remy: when a service worker is being installed, you make sure that the page(s) the user is first visiting get added to a cache.
For the offline page on my website, I’ve been using a mixture of the Cache API and the localStorage API. My service worker script uses the Cache API to store copies of pages for offline retrieval. But I used the localStorage API to store metadata about the page—title, description, and so on. Then, my offline page would rifle through the pages stored in a cache, and retreive the corresponding metadata from localStorage.
It all worked fine, but as soon as I read Remy’s post about the forehead-slappingly brilliant technique he’s using, I knew I’d be switching my code over. Instead of using localStorage—or any other browser API—to store and retrieve metadata, he uses the pages themselves! Using the Cache API, you can examine the contents of the pages you’ve stored, and get at whatever information you need:
I realised I didn’t need to store anything. HTML is the API.
Refactoring the code for my offline page felt good for a couple of reasons. First of all, I was able to remove a dependency—localStorage—and simplify the JavaScript. That always feels good. But the other reason for the warm fuzzies is that I was able to use data instead of metadata.
Many years ago, Cory Doctorow wrote a piece called Metacrap. In it, he enumerates the many issues with metadata—data about data. The source of many problems is when the metadata is stored separately from the data it describes. The data may get updated, without a corresponding update happening to the metadata. Metadata tends to rot because it’s invisible—out of sight and out of mind.
In fact, that’s always been at the heart of one of the core principles behind microformats. Instead of duplicating information—once as data and again as metadata—repurpose the visible data; mark it up so its meta-information is directly attached to the information itself.
So if you have a person’s contact details on a web page, rather than repeating that information somewhere else—in the head of the document, say—you could instead attach some kind of marker to indicate which bits of the visible information are contact details. In the case of microformats, that’s done with class attributes. You can mark up a page that already has your contact information with classes from the h-card microformat.
Here on my website, I’ve marked up my blog posts, articles, and links using the h-entry microformat. These classes explicitly mark up the content to say “this is the title”, “this is the content”, and so on. This makes it easier for other people to repurpose my content. If, for example, I reply to a post on someone else’s website, and ping them with a webmention, they can retrieve my post and know which bit is the title, which bit is the content, and so on.
When I read Remy’s post about using the Cache API to retrieve information directly from cached pages, I knew I wouldn’t have to do much work. Because all of my posts are already marked up with h-entry classes, I could use those hooks to create a nice offline page.
The markup for my offline page looks like this:
<h1>Offline</h1>
<p>Sorry. It looks like the network connection isn’t working right now.</p>
<div id="history">
</div>
I’ll populate that “history” div with information from a cache called “pages” that I’ve created using the Cache API in my service worker.
I’m going to use async/await to do this because there are lots of steps that rely on the completion of the step before. “Open this cache, then get the keys of that cache, then loop through the pages, then…” All of those thens would lead to some serious indentation without async/await.
All async functions have to have a name—no anonymous async functions allowed. I’m calling this one listPages, just like Remy is doing. I’m making the listPages function execute immediately:
(async function listPages() {
...
})();
Now for the code to go inside that immediately-invoked function.
I create an array called browsingHistory that I’ll populate with the data I’ll use for that “history” div.
const browsingHistory = [];
I’m going to be parsing web pages later on, so I’m going to need a DOM parser. I give it the imaginative name of …parser.
const parser = new DOMParser();
Time to open up my “pages” cache. This is the first await statement. When the cache is opened, this promise will resolve and I’ll have access to this cache using the variable …cache (again with the imaginative naming).
const cache = await caches.open('pages');
Now I get the keys of the cache—that’s a list of all the page requests in there. This is the second await. Once the keys have been retrieved, I’ll have a variable that’s got a list of all those pages. You’ll never guess what I’m calling the variable that stores the keys of the cache. That’s right …keys!
const keys = await cache.keys();
Time to get looping. I’m getting each request in the list of keys using a for/of loop:
for (const request of keys) {
...
}
Inside the loop, I pull the page out of the cache using the match() method of the Cache API. I’ll store what I get back in a variable called response. As with everything involving the Cache API, this is asynchronous so I need to use the await keyword here.
const response = await cache.match(request);
I’m not interested in the headers of the response. I’m specifically looking for the HTML itself. I can get at that using the text() method. Again, it’s asynchronous and I want this promise to resolve before doing anything else, so I use the await keyword. When the promise resolves, I’ll have a variable called html that contains the body of the response.
const html = await response.text();
Now I can use that DOM parser I created earlier. I’ve got a string of text in the html variable. I can generate a Document Object Model from that string using the parseFromString() method. This isn’t asynchronous so there’s no need for the await keyword.
const dom = parser.parseFromString(html, 'text/html');
Now I’ve got a DOM, which I have creatively stored in a variable called …dom.
I can poke at it using DOM methods like querySelector. I can test to see if this particular page has an h-entry on it by looking for an element with a class attribute containing the value “h-entry”:
if (dom.querySelector('.h-entry h1.p-name') {
...
}
In this particular case, I’m also checking to see if the h1 element of the page is the title of the h-entry. That’s so that index pages (like my home page) won’t get past this if statement.
Inside the if statement, I’m going to store the data I retrieve from the DOM. I’ll save the data into an object called …data!
const data = new Object;
Well, the first piece of data isn’t actually in the markup: it’s the URL of the page. I can get that from the request variable in my for loop.
data.url = request.url;
I’m going to store the timestamp for this h-entry. I can get that from the datetime attribute of the time element marked up with a class of dt-published.
data.timestamp = new Date(dom.querySelector('.h-entry .dt-published').getAttribute('datetime'));
While I’m at it, I’m going to grab the human-readable date from the innerText property of that same time.dt-published element.
data.published = dom.querySelector('.h-entry .dt-published').innerText;
The title of the h-entry is in the innerText of the element with a class of p-name.
data.title = dom.querySelector('.h-entry .p-name').innerText;
At this point, I am actually going to use some metacrap instead of the visible h-entry content. I don’t output a description of the post anywhere in the body of the page, but I do put it in the head in a meta element. I’ll grab that now.
data.description = dom.querySelector('meta[name="description"]').getAttribute('content');
Alright. I’ve got a URL, a timestamp, a publication date, a title, and a description, all retrieved from the HTML. I’ll stick all of that data into my browsingHistory array.
browsingHistory.push(data);
My if statement and my for/in loop are finished at this point. Here’s how the whole loop looks:
for (const request of keys) {
const response = await cache.match(request);
const html = await response.text();
const dom = parser.parseFromString(html, 'text/html');
if (dom.querySelector('.h-entry h1.p-name')) {
const data = new Object;
data.url = request.url;
data.timestamp = new Date(dom.querySelector('.h-entry .dt-published').getAttribute('datetime'));
data.published = dom.querySelector('.h-entry .dt-published').innerText;
data.title = dom.querySelector('.h-entry .p-name').innerText;
data.description = dom.querySelector('meta[name="description"]').getAttribute('content');
browsingHistory.push(data);
}
}
That’s the data collection part of the code. Now I’m going to take all that yummy information an output it onto the page.
First of all, I want to make sure that the browsingHistory array isn’t empty. There’s no point going any further if it is.
if (browsingHistory.length) {
...
}
Within this if statement, I can do what I want with the data I’ve put into the browsingHistory array.
I’m going to arrange the data by date published. I’m not sure if this is the right thing to do. Maybe it makes more sense to show the pages in the order in which you last visited them. I may end up removing this at some point, but for now, here’s how I sort the browsingHistory array according to the timestamp property of each item within it:
browsingHistory.sort( (a,b) => {
return b.timestamp - a.timestamp;
});
Now I’m going to concatenate some strings. This is the string of HTML text that will eventually be put into the “history” div. I’m storing the markup in a string called …markup (my imagination knows no bounds).
let markup = '<p>But you still have something to read:</p>';
I’m going to add a chunk of markup for each item of data.
browsingHistory.forEach( data => {
markup += `
<h2><a href="${ data.url }">${ data.title }</a></h2>
<p>${ data.description }</p>
<p class="meta">${ data.published }</p>
`;
});
With my markup assembled, I can now insert it into the “history” part of my offline page. I’m using the handy insertAdjacentHTML() method to do this.
document.getElementById('history').insertAdjacentHTML('beforeend', markup);
Here’s what my finished JavaScript looks like:
<script>
(async function listPages() {
const browsingHistory = [];
const parser = new DOMParser();
const cache = await caches.open('pages');
const keys = await cache.keys();
for (const request of keys) {
const response = await cache.match(request);
const html = await response.text();
const dom = parser.parseFromString(html, 'text/html');
if (dom.querySelector('.h-entry h1.p-name')) {
const data = new Object;
data.url = request.url;
data.timestamp = new Date(dom.querySelector('.h-entry .dt-published').getAttribute('datetime'));
data.published = dom.querySelector('.h-entry .dt-published').innerText;
data.title = dom.querySelector('.h-entry .p-name').innerText;
data.description = dom.querySelector('meta[name="description"]').getAttribute('content');
browsingHistory.push(data);
}
}
if (browsingHistory.length) {
browsingHistory.sort( (a,b) => {
return b.timestamp - a.timestamp;
});
let markup = '<p>But you still have something to read:</p>';
browsingHistory.forEach( data => {
markup += `
<h2><a href="${ data.url }">${ data.title }</a></h2>
<p>${ data.description }</p>
<p class="meta">${ data.published }</p>
`;
});
document.getElementById('history').insertAdjacentHTML('beforeend', markup);
}
})();
</script>
I’m pretty happy with that. It’s not too long but it’s still quite readable (I hope). It shows that the Cache API and the h-entry microformat are a match made in heaven.
If you’ve got an offline strategy for your website, and you’re using h-entry to mark up your content, feel free to use that code.
If you don’t have an offline strategy for your website, there’s a book for that.
This is brilliant technique by Remy!
If you’ve got a custom offline page that lists previously-visited pages (like I do on my site), you don’t have to choose between localStorage or IndexedDB—you can read the metadata straight from the HTML of the cached pages instead!
This seems forehead-smackingly obvious in hindsight. I’m totally stealing this.
I have a proposal that I think might alleviate some of the animosity around Google AMP. You can jump straight to the proposal or get some of the back story first…
Google AMP is exactly the kind of framework I’d like to get behind. Unlike most front-end frameworks, its components take a declarative approach—no knowledge of JavaScript required. I think Lea’s excellent Mavo is the only other major framework that takes this inclusive approach. All the configuration happens in markup, and all the styling happens in CSS. Excellent!
But I cannot get behind AMP.
Instead of competing on its own merits, AMP is unfairly propped up by the search engine of its parent company, Google. That makes it very hard to evaluate whether AMP is being used on its own merits. Instead, the evidence suggests that most publishers of AMP pages are doing so because they feel they have to, rather than because they want to. That’s a real shame, because as a library of web components, AMP seems pretty good. But there’s just no way to evaluate AMP-the-format without taking into account AMP-the-ecosystem.
Google AMP ostensibly exists to make the web faster. Initially the focus was specifically on mobile performance, but that distinction has since fallen by the wayside. The idea is that by using AMP’s web components, your pages will be speedy. Though, as Andy Davies points out, this isn’t always the case:
This is where I get confused… https://independent.co.uk only have an AMP site yet it’s performance is awful from a user perspective - isn’t AMP supposed to prevent this?
See also: Google AMP lowered our page speed, and there’s no choice but to use it:
According to Google’s own Page Speed Insights audit (which Google recommends to check your performance), the AMP version of articles got an average performance score of 87. The non-AMP versions? 95.
Publishers who already have fast web pages—like The Guardian—are still compelled to make AMP versions of their stories because of the search benefits reserved for AMP. As Terence Eden reported from a meeting of the AMP advisory committee:
We heard, several times, that publishers don’t like AMP. They feel forced to use it because otherwise they don’t get into Google’s news carousel — right at the top of the search results.
Some people felt aggrieved that all the hard work they’d done to speed up their sites was for nothing.
The Google AMP team are at pains to point out that AMP is not a ranking factor in search. That’s true. But it is unfairly privileged in other ways. Only AMP pages can appear in the Top Stories carousel …which appears above any other search results. As I’ve said before:
Now, if you were to ask any right-thinking person whether they think having their page appear right at the top of a list of search results would be considered preferential treatment, I think they would say hell, yes! This is the only reason why The Guardian, for instance, even have AMP versions of their content—it’s not for the performance benefits (their non-AMP pages are faster); it’s for that prime real estate in the carousel.
From A letter about Google AMP:
Content that “opts in” to AMP and the associated hosting within Google’s domain is granted preferential search promotion, including (for news articles) a position above all other results.
That’s not the only way that AMP pages get preferential treatment. It turns out that the secret to the speed of AMP pages isn’t the web components. It’s the prerendering.
If you’ve ever seen an AMP page in a list of search results, you’ll have noticed the little lightning icon. If you’ve ever tapped on that search result, you’ll have noticed that the page loads blazingly fast!
That’s not down to AMP-the-format, alas. That’s down to the fact that the page has been prerendered by Google before you even went to it. If any page were prerendered that way, it would load blazingly fast. But currently, this privilege is reserved for AMP pages only.
If, after tapping through to that AMP page, you looked at the address bar of your browser, you might have noticed something odd. Even though you might have thought you were visiting The Washington Post, or The New York Times, the URL of the (blazingly fast) page you’re looking at is still under Google’s domain. That’s because Google hosts any AMP pages that it prerenders.
Google calls this “the AMP cache”, but it would be better described as “AMP hosting”. The web page sent down the wire is hosted on Google’s domain.
Here’s that AMP letter again:
When a user navigates from Google to a piece of content Google has recommended, they are, unwittingly, remaining within Google’s ecosystem.
Through gritted teeth, I will refer to this as “the AMP cache”, because that’s what everyone else calls it. But make no mistake, Google is hosting—not caching—these pages.
But why host the pages on a Google domain? Why not prerender the original URLs?
Scott summed up the situation with AMP nicely:
The pitch I think site owners are hearing is: let us host your pages on our domain and we’ll promote them in search results AND preload them so they feel “instant.” To opt-in, build pages using this component syntax.
But perhaps we could de-couple the AMP format from the AMP cache.
That’s what Terence suggests:
My recommendation is that Google stop requiring that organisations use Google’s proprietary mark-up in order to benefit from Google’s promotion.
Instead of granting premium placement in search results only to AMP, provide the same perks to all pages that meet an objective, neutral performance criterion such as Speed Index.
It’s been said before but it would be so good for the web if pages with a Lighthouse score over say, 90 could get into that top search result area, even if they’re not built using Google’s AMP framework. Feels wrong to have to rebuild/reproduce an already-fast site just for SEO.
This was also what I was calling for. But then Malte pointed out something that stumped me. Privacy.
Here’s the problem…
Let’s say Google do indeed prerender already-fast pages when they’re listed in search results. You, a search user, type something into Google. A list of results come back. Google begins pre-rendering some of them. But you don’t end up clicking through to those pages. Nonetheless, the servers those pages are hosted on have received a GET request coming from a Google search. Those publishers now know that a particular (cookied?) user could have clicked through to their site. That’s very different from knowing when someone has actually arrived at a particular site.
And that’s why Google host all the AMP pages that they prerender. Given the privacy implications of prerendering non-Google URLs, I must admit that I see their point.
Still, it’s a real shame to miss out on the speed benefit of prerendering:
Prerendering AMP documents leads to substantial improvements in page load times. Page load time can be measured in different ways, but they consistently show that prerendering lets users see the content they want faster. For now, only AMP can provide the privacy preserving prerendering needed for this speed benefit.
Why is Google’s AMP cache just for AMP pages? (Y’know, apart from the obvious answer that it’s in the name.)
What if Google were allowed to host non-AMP pages? Google search could then prerender those pages just like it currently does for AMP pages. There would be no privacy leaks; everything would happen on the same domain—google.com or ampproject.org or whatever—just as currently happens with AMP pages.
Don’t get me wrong: I’m not suggesting that Google should make a 1:1 model of the web just to prerender search results. I think that the implementation would need to have two important requirements:
Currently, by publishing a page using the AMP format, publishers give implicit approval to Google to host that page on Google’s servers and serve up this Google-hosted version from search results. This has always struck me as being legally iffy. I’ve looked in the AMP documentation to try to find any explicit granting of hosting permission (e.g. “By linking to this JavaScript file, you hereby give Google the right to serve up our copies of your content.”), but no luck. So even with the current situation, I think a clear opt-in for hosting would be beneficial.
This could be a meta element. Maybe something like:
<meta name="caches-allowed" content="google">
This would have the nice benefit of allowing comma-separated values:
<meta name="caches-allowed" content="google, yandex">
(The name is just a strawman, by the way—I’m not suggesting that this is what the final implementation would actually look like.)
If not a meta element, then perhaps this could be part of robots.txt? Although my feeling is that this needs to happen on a document-by-document basis rather than site-wide.
Many people will, quite rightly, never want Google—or anyone else—to host and serve up their content. That’s why it’s so important that this behaviour needs to be opt-in. It’s kind of appalling that the current hosting of AMP pages is opt-in-by-proxy-sort-of.
Which pages should be blessed with hosting and prerendering? The fast ones. That’s sorta the whole point of AMP. But right now, there’s a lot of resentment by people with already-fast websites who quite rightly feel they shouldn’t have to use the AMP format to benefit from the AMP ecosystem.
Page speed is already a ranking factor. It doesn’t seem like too much of a stretch to extend its benefits to hosting and prerendering. As mentioned above, there are already a few possible metrics to use:
Ah, but what if a page has good score when it’s indexed, but then gets worse afterwards? Not a problem! The version of the page that’s measured is the same version of the page that gets hosted and prerendered. Google can confidently say “This page is fast!” After all, they’re the ones serving up the page.
That does raise the question of how often Google should check back with the original URL to see if it has changed/worsened/improved. The answer to that question is however long it currently takes to check back in on AMP pages:
Each time a user accesses AMP content from the cache, the content is automatically updated, and the updated version is served to the next user once the content has been cached.
This proposal does not solve the problem with the address bar. You’d still find yourself looking at a page from The Washington Post or The New York Times (or adactio.com) but seeing a completely different URL in your browser. That’s not good, for all the reasons outlined in the AMP letter.
In fact, this proposal could potentially make the situation worse. It would allow even more sites to be impersonated by Google’s URLs. Where currently only AMP pages are bad actors in terms of URL confusion, opening up the AMP cache would allow equal opportunity URL confusion.
What I’m suggesting is definitely not a long-term solution. The long-term solutions currently being investigated are technically tricky and will take quite a while to come to fruition—web packages and signed exchanges. In the meantime, what I’m proposing is a stopgap solution that’s technically a lot simpler. But it won’t solve all the problems with AMP.
This proposal solves one problem—AMP pages being unfairly privileged in search results—but does nothing to solve the other, perhaps more serious problem: the erosion of site identity.
Currently, Google can assess whether a page should be hosted and prerendered by checking to see if it’s a valid AMP page. That test would need to be widened to include a different measurement of performance, but those measurements already exist.
I can see how this assessment might not be as quick as checking for AMP validity. That might affect whether non-AMP pages could be measured quickly enough to end up in the Top Stories carousel, which is, by its nature, time-sensitive. But search results are not necessarily as time-sensitive. Let’s start there.
Currently, AMP pages can be prerendered without fetching anything other than the markup of the AMP page itself. All the CSS is inline. There are no initial requests for other kinds of content like images. That’s because there are no img elements on the page: authors must use amp-img instead. The image itself isn’t loaded until the user is on the page.
If the AMP cache were to be opened up to non-AMP pages, then any content required for prerendering would also need to be hosted on that same domain. Otherwise, there’s privacy leakage.
This definitely introduces an extra level of complexity. Paths to assets within the markup might need to be re-written to point to the Google-hosted equivalents. There would almost certainly need to be a limit on the number of assets allowed. Though, for performance, that’s no bad thing.
Make no mistake, figuring out what to do about assets—style sheets, scripts, and images—is very challenging indeed. Luckily, there are very smart people on the Google AMP team. If that brainpower were to focus on this problem, I am confident they could solve it.
There will be technical challenges, but hopefully nothing insurmountable.
I honestly can’t see what Google have to lose here. If their goal is genuinely to reward fast pages, then opening up their AMP cache to fast non-AMP pages will actively encourage people to make fast web pages (without having to switch over to the AMP format).
I’ve deliberately kept the details vague—what the opt-in should look like; what the speed measurement should be; how to handle assets—I’m sure smarter folks than me can figure that stuff out.
I would really like to know what other people think about this proposal. Obviously, I’d love to hear from members of the Google AMP team. But I’d also love to hear from publishers. And I’d very much like to know what people in the web performance community think about this. (Write a blog post and send me a webmention.)
What am I missing here? What haven’t I thought of? What are the potential pitfalls (and are they any worse than the current acrimonious situation with Google AMP)?
I would really love it if someone with a fast website were in a position to say, “Hey Google, I’m giving you permission to host this page so that it can be prerendered.”
I would really love it if someone with a slow website could say, “Oh, shit! We’d better make our existing website faster or Google won’t host our pages for prerendering.”
And I would dearly love to finally be able to embrace AMP-the-format with a clear conscience. But as long as prerendering is joined at the hip to the AMP format, the injustice of the situation only harms the AMP project.
Google, open up the AMP cache.
It seems that some code that I wrote in Going Offline is haunted. It’s the trimCache function.
First, there was the issue of a typo. Or maybe it’s more of a brainfart than a typo, but either way, there’s a mistake in the syntax that was published in the book.
Now it turns out that there’s also a problem with my logic.
To recap, this is a function that takes two arguments: the name of a cache, and the maximum number of items that cache should hold.
function trimCache(cacheName, maxItems) {
First, we open up the cache:
caches.open(cacheName)
.then( cache => {
Then, we get the items (keys) in that cache:
cache.keys()
.then(keys => {
Now we compare the number of items (keys.length) to the maximum number of items allowed:
if (keys.length > maxItems) {
If there are too many items, delete the first item in the cache—that should be the oldest item:
cache.delete(keys[0])
And then run the function again:
.then(
trimCache(cacheName, maxItems)
);
A-ha! See the problem?
Neither did I.
It turns out that, even though I’m using then, the function will be invoked immediately, instead of waiting until the first item has been deleted.
Trys helped me understand what was going on by making a useful analogy. You know when you use setTimeout, you can’t put a function—complete with parentheses—as the first argument?
window.setTimeout(doSomething(someValue), 1000);
In that example, doSomething(someValue) will be invoked immediately—not after 1000 milliseconds. Instead, you need to create an anonymous function like this:
window.setTimeout( function() {
doSomething(someValue)
}, 1000);
Well, it’s the same in my trimCache function. Instead of this:
cache.delete(keys[0])
.then(
trimCache(cacheName, maxItems)
);
I need to do this:
cache.delete(keys[0])
.then( function() {
trimCache(cacheName, maxItems)
});
Or, if you prefer the more modern arrow function syntax:
cache.delete(keys[0])
.then( () => {
trimCache(cacheName, maxItems)
});
Either way, I have to wrap the recursive function call in an anonymous function.
Here’s a gist with the updated trimCache function.
What’s annoying is that this mistake wasn’t throwing an error. Instead, it was causing a performance problem. I’m using this pattern right here on my own site, and whenever my cache of pages or images gets too big, the trimCaches function would get called …and then wouldn’t stop running.
I’m very glad that—witht the help of Trys at last week’s Homebrew Website Club Brighton—I was finally able to get to the bottom of this. If you’re using the trimCache function in your service worker, please update the code accordingly.
Management regrets the error.
When I was writing about the lie-fi strategy I’ve added to adactio.com, I finished with this thought:
What I’d really like is some way to know—on the client side—whether or not the currently-loaded page came from a cache or from a network. Then I could add some kind of interface element that says, “Hey, this page might be stale—click here if you want to check for a fresher version.”
Trys heard my plea, and came up with a very clever technique to alter the HTML of a page when it’s put into a cache.
It’s a function that reads the response body stream in, returning a new stream. Whilst reading the stream, it searches for the character codes that make up:
<html. If it finds them, it tacks on adata-cachedattribute.
Nice!
But then I was discussing this issue with Tantek and Aaron late one night after Indie Web Camp Düsseldorf. I realised that I might have another potential solution that doesn’t involve the service worker at all.
Caveat: this will only work for pages that have some kind of server-side generation. This won’t work for static sites.
In my case, pages are generated by PHP. I’m not doing a database lookup every time you request a page—I’ve got a server-side cache of posts, for example—but there is a little bit of assembly done for every request: get the header from here; get the main content from over there; get the footer; put them all together into a single page and serve that up.
This means I can add a timestamp to the page (using PHP). I can mark the moment that it was served up. Then I can use JavaScript on the client side to compare that timestamp to the current time.
I’ve published the code as a gist.
In a script element on each page, I have this bit of coducken:
var serverTimestamp = <?php echo time(); ?>;
Now the JavaScript variable serverTimestamp holds the timestamp that the page was generated. When the page is put in the cache, this won’t change. This number should be the number of seconds since January 1st, 1970 in the UTC timezone (that’s what my server’s timezone is set to).
Starting with JavaScript’s Date object, I use a caravan of methods like toUTCString() and getTime() to end up with a variable called clientTimestamp. This will give the current number of seconds since January 1st, 1970, regardless of whether the page is coming from the server or from the cache.
var localDate = new Date();
var localUTCString = localDate.toUTCString();
var UTCDate = new Date(localUTCString);
var clientTimestamp = UTCDate.getTime() / 1000;
Then I compare the two and see if there’s a discrepency greater than five minutes:
if (clientTimestamp - serverTimestamp > (60 * 5))
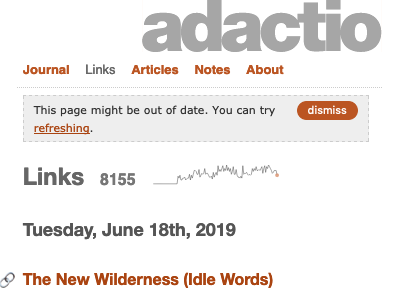
If there is, then I inject some markup into the page, telling the reader that this page might be stale:
document.querySelector('main').insertAdjacentHTML('afterbegin',`
<p class="feedback">
<button onclick="this.parentNode.remove()">dismiss</button>
This page might be out of date. You can try <a href="javascript:window.location=window.location.href">refreshing</a>.
</p>
`);
The reader has the option to refresh the page or dismiss the message.
It’s not foolproof by any means. If the visitor’s computer has their clock set weirdly, then the comparison might return a false positive every time. Still, I thought that using UTC might be a safer bet.
All in all, I think this is a pretty good method for detecting if a page is being served from a cache. Remember, the goal here is not to determine if the user is offline—for that, there’s navigator.onLine.
The upshot is this: if you visit my site with a crappy internet connection (lie-fi), then after three seconds you may be served with a cached version of the page you’re requesting (if you visited that page previously). If that happens, you’ll now also be presented with a little message telling you that the page isn’t fresh. Then it’s up to you whether you want to have another go.
I like the way that this puts control back into the hands of the user.
Trust no one! Harry enumerates the reason why you should be self-hosting your assets (and busts some myths along the way).
There really is very little reason to leave your static assets on anyone else’s infrastructure. The perceived benefits are often a myth, and even if they weren’t, the trade-offs simply aren’t worth it. Loading assets from multiple origins is demonstrably slower.
Less than 24 hours after I put the call out for a solution to this gnarly service worker challenge, Trys has come up with a solution.