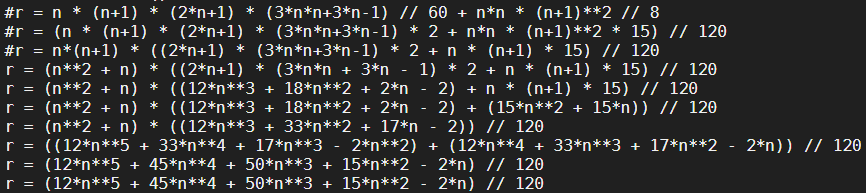
I am trying to efficiently compute a summation of a summation in Python:
WolframAlpha is able to compute it too a high n value: sum of sum.
I have two approaches: a for loop method and an np.sum method. I thought the np.sum approach would be faster. However, they are the same until a large n, after which the np.sum has overflow errors and gives the wrong result.
I am trying to find the fastest way to compute this sum.
import numpy as np
import time
def summation(start,end,func):
sum=0
for i in range(start,end+1):
sum+=func(i)
return sum
def x(y):
return y
def x2(y):
return y**2
def mysum(y):
return x2(y)*summation(0, y, x)
n=100
# method #1
start=time.time()
summation(0,n,mysum)
print('Slow method:',time.time()-start)
# method #2
start=time.time()
w=np.arange(0,n+1)
(w**2*np.cumsum(w)).sum()
print('Fast method:',time.time()-start)

{kind=link}
non Wolfram Alpha. You're done.